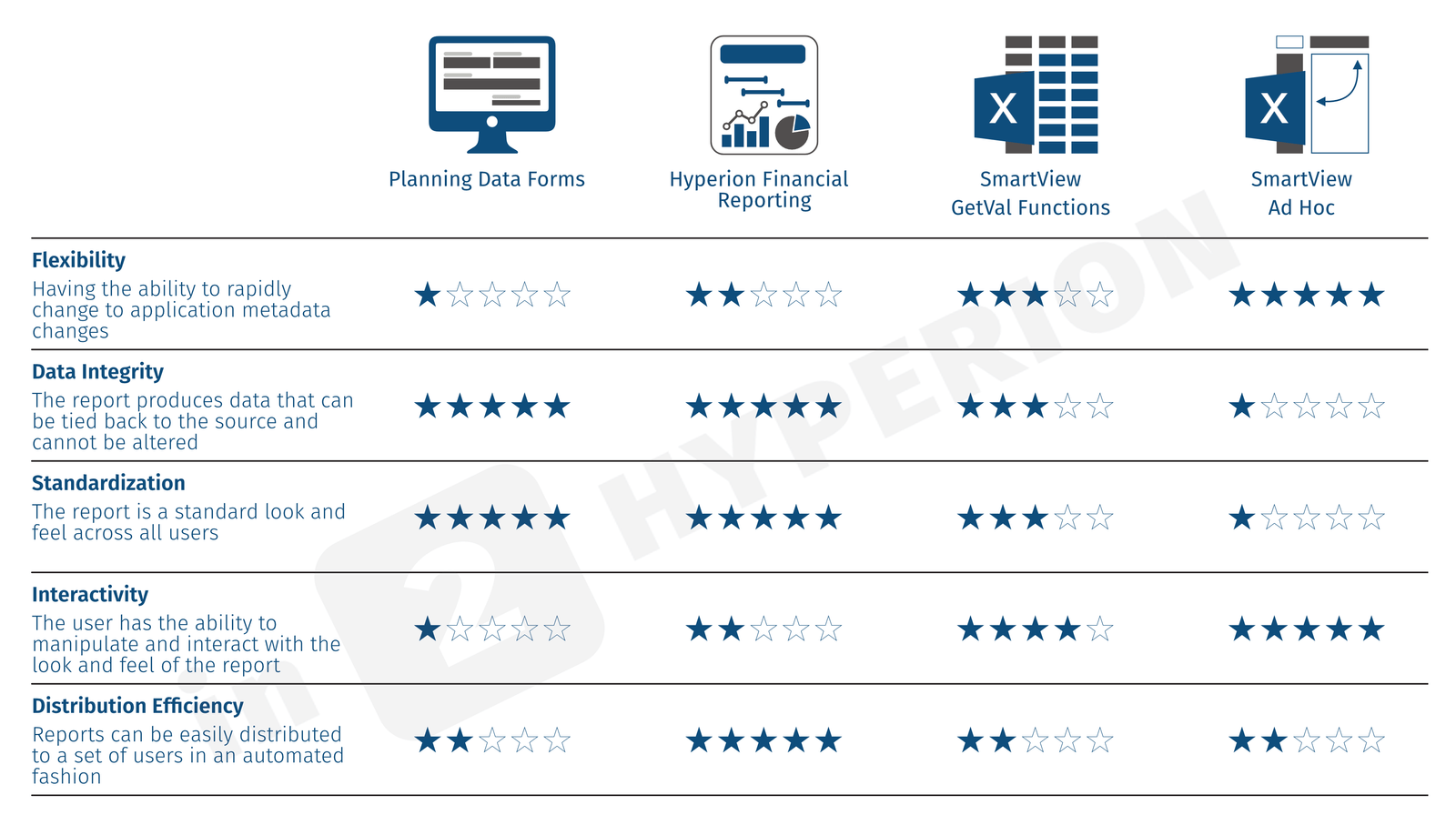
What Is Groovy
Recently, Groovy scripting was added to ePBCS business rules as an option instead of the GUI, or the go-to scripting for you old-timers who still refuse to change. These are defined in the Business Rule editor as Groovy calculations. So, what is Groovy?
 “Apache Groovy is an object-oriented programming language for the Java platform. It is a dynamic language with features similar to those of Python, Ruby, Perl, and Smalltalk. It can be used as a scripting language for the Java Platform, is dynamically compiled to Java virtual machine (JVM) bytecode, and interoperates with other Java code and libraries. Groovy uses a Java-like curly-bracket syntax. Most Java code is also syntactically valid Groovy, although semantics may be different.”
“Apache Groovy is an object-oriented programming language for the Java platform. It is a dynamic language with features similar to those of Python, Ruby, Perl, and Smalltalk. It can be used as a scripting language for the Java Platform, is dynamically compiled to Java virtual machine (JVM) bytecode, and interoperates with other Java code and libraries. Groovy uses a Java-like curly-bracket syntax. Most Java code is also syntactically valid Groovy, although semantics may be different.”
If you haven’t heard of Groovy, you may want to do some research. Oracle is using more and more Groovy in applications as administrative options and a communication method between applications. Groovy is a standard and can be used with millions of applications and websites with the REST API.
What Groovy Script/Calculations Are Not
Groovy calculations are not java-based calculations. It is not a new calculation language. It does provide a way to interact with a Data Form in ePBCS and build a calculation script dynamically. So, Groovy, in the context of Groovy Calculation Scripts, does not connect to Essbase via Groovy Business Rules. It simply builds a string that is sent to Essbase as a calculation. It does, however, interact with Planning and that is where the power starts. With the ability to have all the Groovy functionality to manipulate strings and now the ability to interact with the data form, dynamic calculations can be built. The calculation script sent to Essbase is no different, but the script can now be dynamically generated based on things like, the POV, the text value of a Smart List, whether the values in the grid were updated, whether the data entered meets validation criteria, and other similar things.
If you are experienced with Hyperion Planning, you may have dabbled with JavaScript to do data validation, calculate data prior to the user submitting it, or prevent users from submitting data. It was a great option to provide feedback to users, but that basically was useless when Smart View allowed users to open Data Forms in Excel. The JavaScript did nothing unless the form was opened in an internet browser.
Getting Started
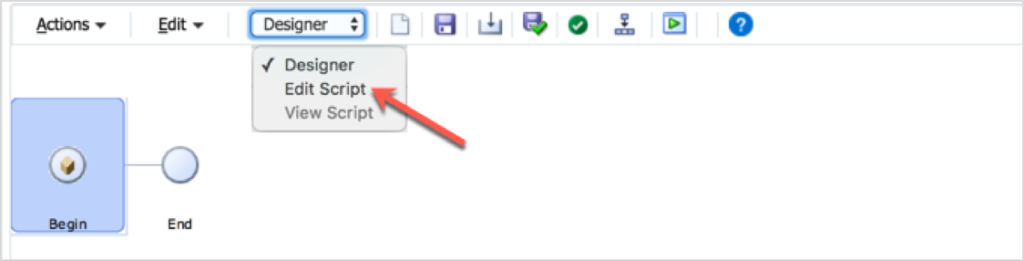
The first step in creating a Groovy Calculation Script is to, well, create one. To do that, create a new business rule. Change the view from Designer to Edit Script. If you haven’t noticed this before, it provides a way to toggle the GUI to a script view.
Next, find the drop-down box in the toolbar to the far right named Script Type. This option will read Calc Script. Change it to Groovy Script.
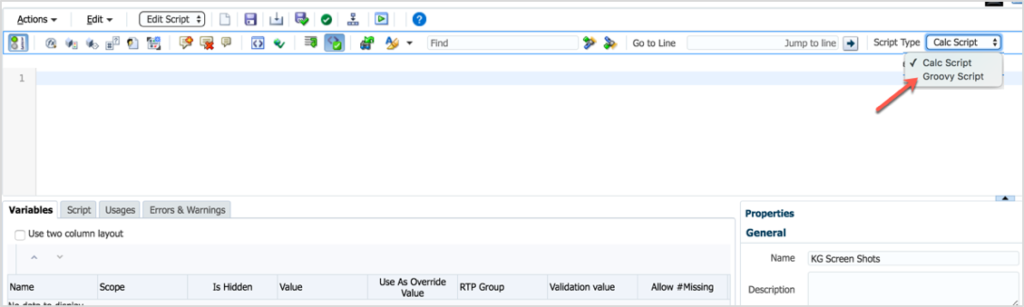
AAt this point, the script window is now set to validate Groovy script, not Essbase syntax. Even though it doesn’t do anything yet, you have just created your first Groovy Business Rule!
Use Cases
There is a lot of potential in this functionality. To get you thinking, here are some examples:
- Execute calculations on large sparse dimensions on ONLY the members that changed on the form.
- Access the Smart List text to do validation, use in calculations, and store for later use in Essbase (maybe save a member name in a member that is numeric, like employee ID, Cost Center, or account).
- Perform validation before the calculation is built and sent to Essbase. For example, if the sum of a column used to allocate dollars doesn’t sum to 100, send a calculation that ONLY returns a message and doesn’t perform the allocation.
- Perform text manipulation previously done in Essbase with functions. Concatenating member names and truncating member name prefixes and date formats are some of the few I use regularly. Many of these functions are extremely slow and force the calculation to execute in serial mode, so to be able to do them outside the script is now an option.
Real World Example
The Problem
I am working with a client who wants to override the result of driver-based calculations based on historical trends. In this example, the volume of cases can be changed and the profit rate can be adjusted. Once the form is saved, the overrides need to be removed.
Here-in lies the challenge. If the overrides are removed and the calculation runs on all members in the form, the results would revert back to what they were prior to the override because the override values no longer exist in the database or Data Form. So, rather than perform the calculation on the override, it would use #missing or zero, and take the results right back to what the drivers dictated. The most obvious way around this issue is to execute the calculation on ONLY the rows (vendors in this example) that were edited. In other words, dynamically generate the FIX statement on the vendors that were updated.
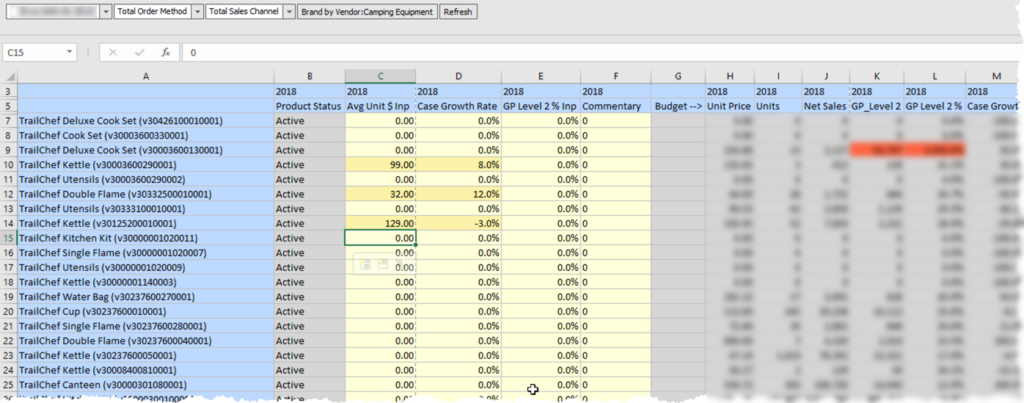
The Non-Groovy FIX Statement
Without Groovy, the FIX statement would include @RELATIVE(“Vendor”,0) to run the calculation on all venders on the Data Form. This has 2 issues. One, it calculates all the vendors and will change the vendors back to the pre-override values. Two, every time the user saves the form, the fix is traversing through 30,000 possible vendors. Although most companies have less than 8,000 active vendors, it still poses a performance issue calculating 8,000 blocks when only a few typically change.
The only aspect of the calculation that is going to change in this situation is the FIX statement, so that will be the only piece shown in the comparison between a Groovy script and a non-Groovy script.
FIX(&vScenario,
&vVersion,
&vCompany,
&vYear,
"Local",
"Input",
@RELATIVE(“Vendor”,0),
"Jan":"Dec",
"Regular_Cases")
The Groovy FIX Statement
Since Groovy can dynamically create the calculation script, it looks more like the example below. The sPov will be a string variable in Groovy that holds all the members in the data form’s POV. The sVendors Groovy variable will hold the list of vendors that have been edited.
FIX($sPOV
$sVendors,
"Jan":"Dec",
"Regular_Cases")
@RELATIVE(“Vendor”,0), which would produce a list of every vendor in the hierarchy, is replaced with “V300000300040003”, “V300000300060001”, “V300000300070002”.
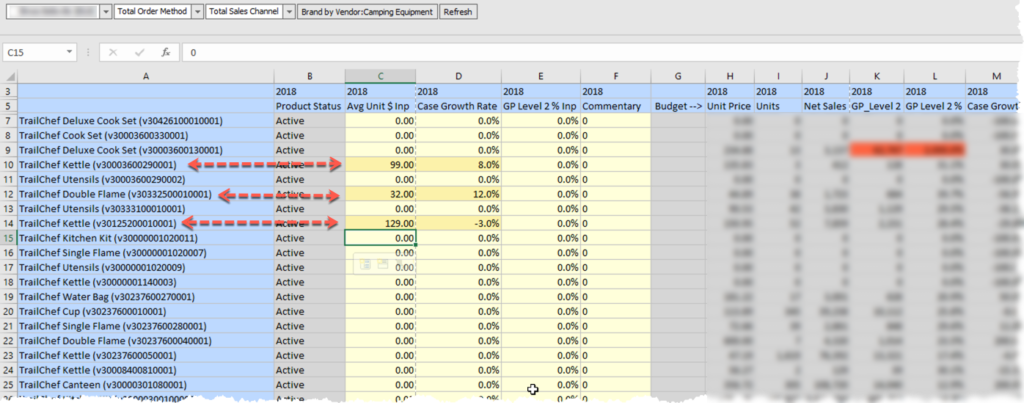
The issue of running the calculation on vendors that have not been edited has now been solved. An added benefit is that the calculation runs on 3 of the 8,000 blocks, so what took 30 seconds now completes in under a second.
Now, The Interesting Part
Let’s dissect the Groovy calculation script piece by piece.
Setting The Stage
For Groovy to perform operations, there are a few housekeeping items that need to be addressed. First, a few string builders need to be created to store some variables of strings that grow through the process and are concatenated to Essbase calculation before it is submitted for processing.
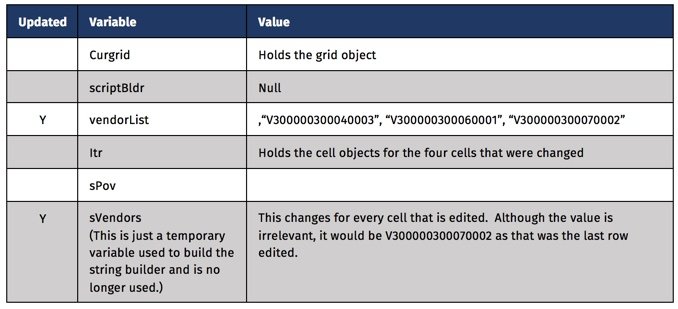
There are some variables used to interact with the form’s data grid. For easy reference to the grid through the script, the grid object is stored in a variable (curgrid). Next, a variable is created to hold the result of the cells that have been edited (itr). The likelihood that these variables would exist in most of the scripts is high, so it might make sense to get familiar with these objects and their parameters.
//Get current Data Form
DataGrid curgrid = operation.getGrid()
// Construct a string builder
// Holds the calculation script sent to Essbase
StringBuilder scriptBldr = StringBuilder.newInstance()
// Holds the value for the venders that have changed
StringBuilder vendorList = StringBuilder.newInstance()
String sVendors
// Iterater which gives you only the edited cells
GridIterator itr = curgrid.getDataCellIterator(PredicateUtils.invokerPredicate("isEdited"))
// Holds the list of members from the POV – the function returns an array, so this
// parsed the array and places quotes around each member and separates them with a comma
String sPov = '"' + curgrid.getPov().essbaseMbrName.join(',').replaceAll(',','","') + '"'
At this point the values of the variables are as follows.

Find the Vendors That Have Changed
We know the users will enter overrides in this Data Form (Case Growth and Average Price). The following piece of the Groovy script will build a delimited list of those vendors based on the rows that have been edited. It will include quotes around the member names to account for any member names that are numeric or have special characters and will be separated by a comma. Groovy provides the ability to append to a string with <<”””, and close it with “””. The if statement ensures that a vendor will not be appended to the string if multiple columns are changed.
// Loop through each cell that was edited and build the vendor list
// If multiple cells on the same row are edited, only add vendor once
itr.each{ DataCell cell ->
sVendors = cell.getMemberName("Vendor")
if(vendorList.indexOf(sVendors) < 0){
vendorList <<"""
,"$sVendors"
"""
}
}
At this point, only a few variables have changed. The bulk of the Groovy functionality is finished. We now have the POV and the list of vendors that need to be in the FIX statement.
The Essbase Calculation
The next section will append text to the scriptBldr string. This string will ultimately be sent to Essbase as the calculation to be performed. Groovy variables are embedded and replaced with the value that they were set to previously. The two used in this calculation are $vendorList and $sPOV. Other than those two pieces, everything else is pulled from the original Business Rule and highlighted in red below.
// Add the calculation defined in a business rule to the string variable
// the POV and Vendor List will be used to dynamically set the FIX statement
scriptBldr <<"""
VAR v_Price;
FIX($sPOV
$vendorList,
"Jan":"Dec",
"Regular_Cases")
/* Calculate Overrides */
"OEP_Working"(
v_Price = "Avg_Price/Case"->"YearTotal";
"Regular_Cases" = (1 + "Case_Growth_Rate"->"BegBalance") *
("Regular_Cases"->"FY16"->"Final");
IF("Avg_Price/Case_Inp"->"BegBalance" == #Missing)
"Net_Sales" = (v_Price) * (1 + "Case_Growth_Rate"->"BegBalance") *
"Regular_Cases"->"FY16"->"Final";
ELSE
"Net_Sales" = ("Avg_Price/Case_Inp"->"BegBalance") *
(1 + "Case_Growth_Rate"->"BegBalance") *
"Regular_Cases"->"FY16"->"Final" ;
ENDIF
IF("GP_2_%_Inp"->"BegBalance" == #Missing)
"GP_Level_2" = ("GP_Level_2_%"->"YearTotal"->"FY16"->"Final") * "Net_Sales" ;
ELSE
"GP_Level_2" = ("GP_2_%_Inp"->"BegBalance") * "Net_Sales" ;
ENDIF
)
ENDFIX
FIX($sPOV
$vendorList)
CLEARDATA "Avg_Price/Case_Inp"->"BegBalance";
CLEARDATA "GP_2_%_Inp"->"BegBalance";
CLEARDATA "Case_Growth_Rate"->"BegBalance";
ENDFIX
"""
At this point, the scriptBldr variable is a complete Essbase calculation that can be validated in any Business Rule.
Finishing UP
The last thing required is to send the calculation text built above to Essbase.
println scriptBldr // Sends the script to the log
return scriptBldr // Sends the script to Essbase
Verifying What Was Sent To Essbase
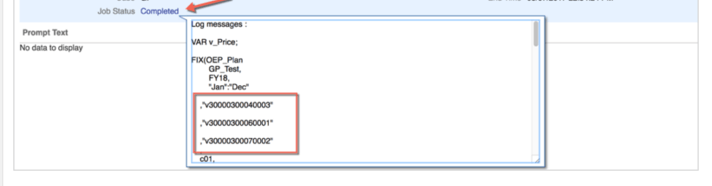
When the Data Form is saved, the results in the form can be validated back to the logic to verify that the calculation worked as expected. Regardless of whether the calculation executes with or without failing, the value of scriptBldr ( calculation sent to Essbase) is captured in the Job console.
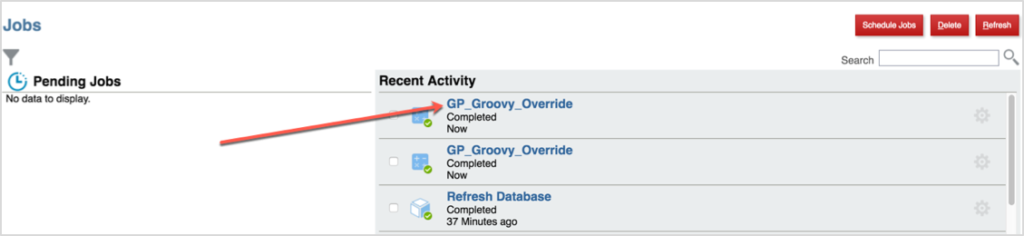
In the Job console, click the Job Status link. This includes the value of the scriptBldr variable. The text can be copied from this window, and if it failed to execute, can be copied into a Business Rule and validated there to find the issue.
Wrapping Up
I will admit that I am not a Java programmer, so I am still educating myself on the potential this affords developers. I am struggling to digest the API documentation and to truly understand the depth of the possibilities. I do know this opens up a whole world we didn’t have with Hyperion Planning. I plan on learning and using Groovy calculations more and more because of the possibilities it provides. Look for more examples and knowledge sharing as I get my hands around the API and integrate this into more delivery solutions. To get future publications, sign up to be notified about new posts and articles at www.in2hyperion.com.