Because so many methods in PBCS require parameters that are maps and lists, it is very important to your productivity and effectiveness to understand, use, and be able to manipulate collections. Collections include lists, maps, and ranges. These are based on Java collection types and include a ton of useful methods. This article will cover lists and maps.
- Lists are objects that are embedded in brackets and separated by commas, like [Jan, Feb, Mar].
- Maps are also known as associative arrays and are similar to lists. Each element is separated by a colon, like [Revenue:678979, Expense:34387].
Not to jump too far ahead, but these objects aren’t limited to holding strings. They can hold numeric values, lists inside of lists, maps inside of lists, or really almost any combination of these objects.
Time Well Spent
There is a lot of information in this post. Before you page down, or read a little and get bored, I highly recommend you invest the time and understand the content. The feedback from everybody that I gave this information to prior to this post said it made a huge impact and really cleared up a lot of questions they had.
A Little About Lists and Maps And Why Understanding It Is Important
Lists and Maps are used in a number of places that are frequently used in Groovy calculations. Gridbuilder and DataMap objects are dependent on these objects. You may be building the POV by embedding strings into what is actually a list without even knowing it. I have done this in previous examples to keep it simple and explainable.
String sYear = '"' + operation.grid.pov.find{it.dimName =='Years'}.essbaseMbrName + '"'
String sScenario = '"' + operation.grid.pov.find{it.dimName =='Scenario'}.essbaseMbrName + '"'
String sCompany = operation.grid.getCellWithMembers().getMemberName("Company")
String sChannel = '"' + operation.grid.pov.find{it.dimName =='Channel'}.essbaseMbrName + '"'
String sMaterialGroup = '"' + operation.grid.pov.find{it.dimName =='Material_Group'}.essbaseMbrName + '"'
operation.application.getDataMap("[name of map]").execute(["Company":sCompany,"Channel":sChannel,"Material_Group":sMaterialGroup,"Vendor":sVendor,"Scenario":sScenario,"Version":"OEP_Working","Years":sYear,"Source":"NBF_Source","Currency":"Local,USD","Account":accountPush],true)
builder.addPov(['Years', 'Scenario', 'Version', 'Company','Channel','Material_Group','Source','Vendor','View'], [sYear.tokenize(), sScenario.tokenize(), ['OEP_Working'], [sCompany],['Tot_Channel'],['Total_Material_Group'],['Tot_Source'],['Tot_Vendor'],['MTD']])
Since the POV and DataMap include lists and maps, building them can also be done by pulling the grid POV, which is a map. Lists can be extracted from the map. There are some additional members that are required that are not in the Web Form, so a few dimensions have to be added.
Hopefully the following example will emphasize the importance of understanding these objects and the methods associated to them. The above is not a ton of work, but replicating this hundreds of times and having the foresight to think about how functions can be reused highlights why understanding lists, and understanding Groovy, will help you provide solutions that are more manageable to maintain. The following replicates what was above in a more effective and readable way, in my opinion. It may seem more complex, but give it a chance. I think you will find it easier once you understand it, and less work to develop Groovy calculations.
Example Setup
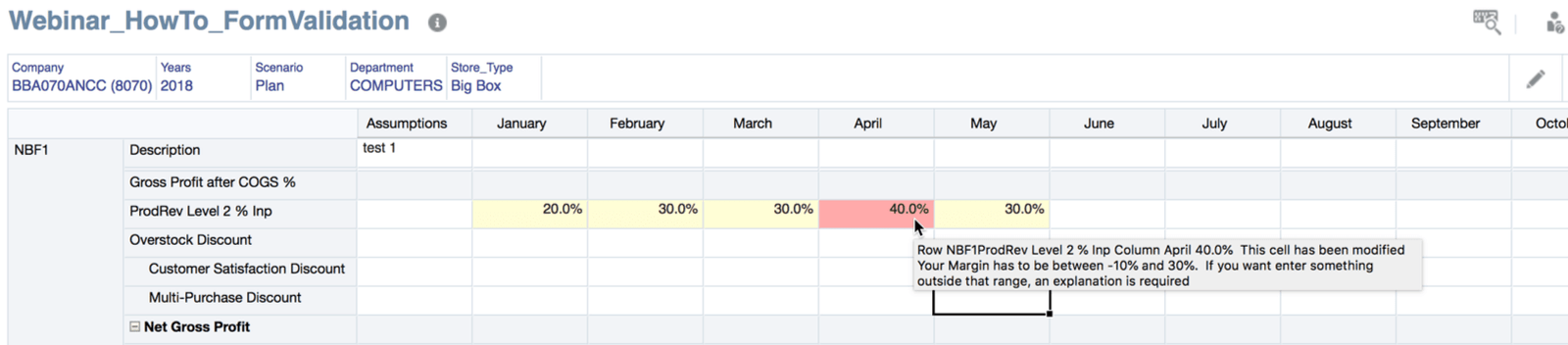
Assume the user changes Units for Jan, Feb, and Mar for NBF1 in the Data Form below. Net Sales is impacted as it is calculated. The business rule that runs calculates currency, so that will also have to be included in the DataMap and GridBuilder.

The POV for the form looks like this.

Replicating The DataMap Using A Groovy Map Object
Executing a Data Map uses a Groovy map built from the Data Form POV. Currency has to be altered. The edited rows and columns are appended. For a complete explanation of how to get the edited cells, read Part 3: Acting On Edited Cells.
// Create a map from the data form POV
def povMap = [:]
operation.grid.pov.each{povMap[$it.dimName] = $it.essbaseMbrName}
// Update Currency to include Local AND USD
povMap['Currency'] = 'Local,USD'
// Add the vendor and accounts that have been changed
povMap2.put('Period', sPeriods)
povMap2.put('Account', accountPush)
povMap2.put ('Vendor', sVendor)
// Execute the data map with all the dimensional overrides
operation.application.getDataMap("[name of generic map]").execute(povMap,true)
Let’s walk through the results of the script. The povMap when created from the Data Form starts with
- [Version:OEP_Working,
- Source:NBF_Source,
- Currency:Local,
- Company:BILB,
- Years:FY18,
- Scenario:OEP_Plan,
- Material_Group:mI03,
- Channel:c01]
Once this map is created, there are some edits made.
- Currency is changed from Local to Local, USD.
- Periods is added as Jan, Feb, Mar.
- Account is added as Units, Net_Sales.
- Vendors is added as NBF1.
This method requires fewer lines, is much easier to repeat, is easier to read, and can be reused for other functions.
Replicating The GridBuilder POV Using A Groovy Map Object
Assume the data is now going to be replicated to another cube using a GridBuilder. In the example available in Part 21: Real Time Data Movement (Getting REALLY Groovy), the data is moved to a P&L cube at a summary level and doesn’t include the channel, material group, and vendor dimensions. A new Groovy map can be created (which we will do here), or we can alter the existing one above. The source grid would then need to pull data at the total of all these dimensions. Currency and Period need to be removed as they are in the columns. Account will be removed and placed in the rows.
def povGridMap = [:]
operation.grid.pov.each{povGridMap[it.dimName] = it.essbaseMbrName}
// Remove dimensions that will be in the rows and columns
povGridMap.remove('Currency')
// Add View dimiension
povGridMap['View'] = 'MTD'
// Change the dimensions that need to pull totals
povGridMap['Channel'] = 'Total_Channel'
povGridMap['Material_Group'] = 'Total_Material_Group'
povGridMap['Vendor'] = 'Total_Vendor' // Another way to add a new element to the map
builder.addPov(povGridMap.keySet() as List, povGridMap.values().collect{[it]} as List)
// the reason this requires the as List notation is because the addPOV method requires
// the parameter to be a list type
// From the Java Docs:
// void setPov(java.util.List<java.lang.String> dimensions,
// java.util.List<java.util.List<java.lang.String>> members)
Let’s walk through the results of the script. The povMap when created from the Data Form starts with
- [Version:OEP_Working,
- Source:NBF_Source,
- Currency:Local,
- Company:BILB,
- Years:FY18,
- Scenario:OEP_Plan,
- Material_Group:mI03,
- Channel:c01]
The edits are then made and the result is
- [Version:OEP_Working,
- Source:NBF_Source,
- Company:BILB,
- Years:FY18,
- Scenario:OEP_Plan,
- Material_Group:Total_Material_Group,
- Channel:Total_Channel,
- Vendor:Total_Vendor]
Moving On
Hopefully the difference in the two strategies inspires you to learn a little more about the objects and methods below.
The remainder of this article shows examples that will be extremely useful, and some that will just give you some insight to what is possible.
Lists
Creating And Editing Lists
Lists can be created and referenced a number of ways. Empty lists can be created.
def emptyList = []
Lists can be created by adding the elements.
Def q1List = [‘Jan’,’Feb’,’Mar’]
Lists can be altered by adding new elements.
def q2List = [‘Apr’]
q2List << (‘May’)
q2List.add(‘Jun’)
or
q2List.addAll(['Apr', 'May', 'Jun'])
They can even be added at specific places.
def q2List = ['Apr']
q2List << ('Jun')
q2List.put(1,'May') // which places it after Apr and before Jun
Elements can be edited based on location.
q2List.set(1,'May') // second item
q2List[-2]'May' // go back 2 from end
q2List[1]'May' / second item
Elements can be removed from lists.
q2List << (‘Jul’)
q2List.remove('Jul')
or
q2List.removeIf{it == 'Jul'}
or
['a','b','c','b','b'] - ['b','c'] // result is ['a']
Iterating Lists
Iterating on elements of a list is usually done by using one of the following.
- each
- eachWithIndex (same as each but include the index of the element)
['Jan','Feb','Mar'].each { month ->
println "Item: $month"
}
// With the index of the element
['Jan','Feb','Mar'].eachWithIndex { month, index ->
println "Item: $month is index $index"
}
The list can be altered while iterating, too. This doesn’t update the list. It only produces a new list.
println [1, 2, 3].collect { it * 2 } //would produce [2, 4, 6]
Manipulating lists
Filtering and searching
There are tons of filtering and searching options. The following are examples, but it isn’t even close to an exhaustive list. Hopefully it will inspire some thought as to how you can use these methods.
// find 1st element matching criteria
[1, 2, 3].find { it > 1 } // results in 2
// find all elements matching criteria
[1, 2, 3].findAll { it > 1 } // results in [2, 3]
// find index of 1st element matching criteria
['a', 'b', 'c', 'd', 'e'].findIndexOf {it in ['c', 'e', 'g']} // results in 2
['a', 'b', 'c', 'd', 'c'].indexOf('c') // index returned (2)
['a', 'b', 'c', 'd', 'c'].indexOf('z') // index -1 means value not in list
['a', 'b', 'c', 'd', 'c'].lastIndexOf('c') // 4 is returned
[1, 2, 3].every { it < 5 } // returns true if all elements match the predicate
![1, 2, 3].every { it < 3 }
[1, 2, 3].any { it > 2 } // returns true if any element matches the predicate
![1, 2, 3].any { it > 3 }
[1, 2, 3, 4, 5, 6].sum() == 21 // sum anything with a plus() method
['a', 'b', 'c', 'd', 'e'].sum() // 'abcde'
[['a', 'b'], ['c', 'd']].sum() // ['a', 'b', 'c', 'd']
// an initial value can be provided
[].sum(1000) // 1000
[1, 2, 3].sum(1000) // 1006
[1, 2, 3].join('-') // '1-2-3'
def list = [9, 4, 2, 10, 5]
list.max() // 10
list.min() // 2
// we can also compare single characters, as anything comparable
assert ['x', 'y', 'a', 'z'].min() // 'a'
// we can use a closure to specify the sorting behavior
def list2 = ['abc', 'z', 'xyzuvw', 'Hello', '321']
list2.max { it.size() } // 'xyzuvw'
list2.min { it.size() } // 'z'
['a','b','c'].contains('a') // true
[1,3,4].containsAll([1,4]) // true
[1,2,3,3,3,3,4,5].count(3) // 4
Sorting
Groovy offers a variety of options to sort lists, from using closures to comparators.
[6, 3, 9, 2, 7, 1, 5].sort() // [1, 2, 3, 5, 6, 7, 9]
def list = ['abc', 'z', 'xyzuvw', 'Hello', '321']
list.sort {it.size()} // ['z', 'abc', '321', 'Hello', 'xyzuvw']
def list2 = [7, 4, -6, -1, 11, 2, 3, -9, 5, -13]
Maps
Literals
In Groovy, maps (also known as associative arrays) can be created using the map literal syntax: [:]. Maps are use to create associations between two or more elements. They can be used to lookup values like currency rates, map accounts from one plan type to another, and a host of other things. Many of the API methods require maps to be passed.
def map = [name: 'Gromit', likes: 'cheese', id: 1234]
map.get('name') // 'Gromit'
map.get('id') // 1234
map['name'] // 'Gromit'
map['id'] == 1234
def emptyMap = [:]
emptyMap.size() // 0
emptyMap.put("foo", 5)
emptyMap.size() // 1
emptyMap.get("foo") // 5
Map Notation
Maps also act like joins so you can use the property notation to get/set items inside the Map as long as the keys are strings which are valid Groovy identifiers:
def map = [name: 'Gromit', likes: 'cheese', id: 1234]
map.name // 'Gromit' - can be used instead of map.get('name')
map.id // 1234
def emptyMap = [:]
emptyMap.size() // 0
emptyMap.foo = 5
emptyMap.size() // 1
emptyMap.foo // 5
Iterating Maps
Maps makes use of the each and eachWithIndex methods to itarate through maps, just like Lists.
def map = [
Bob : 42,
Alice: 54,
Max : 33
]
// Loop through each item
map.each { entry ->
println "Name: $entry.key Age: $entry.value"
}
// add an index
map.eachWithIndex { entry, i ->
println "$i - Name: $entry.key Age: $entry.value"
}
// Alternatively you can use key and value directly
map.each { key, value ->
println "Name: $key Age: $value"
}
// Key, value and i as the index in the map
map.eachWithIndex { key, value, i ->
println "$i - Name: $key Age: $value"
Manipulating Maps
Adding/Removing Elements
Adding an element to a map can be done either using the put method, the subscript operator or using putAll.
def defaults = [1: 'a', 2: 'b', 3: 'c', 4: 'd']
def overrides = [2: 'z', 5: 'x', 13: 'x']
def result = new LinkedHashMap(defaults)
result.put(15, 't')
result[17] = 'u'
result.putAll(overrides) // [1: 'a', 2: 'z', 3: 'c', 4: 'd', 5: 'x', 13: 'x', 15: 't', 17: 'u']
Removing all the elements of a map can be done by calling the clear method:
def m = [1:'a', 2:'b']
println m.get(1) // 'a'
m.clear()
Filtering and searching
It is useful to search and filter maps, and here are some examples of this functionality.
def people = [
1: [name:'Bob', age: 32, gender: 'M'],
2: [name:'Johnny', age: 36, gender: 'M'],
3: [name:'Claire', age: 21, gender: 'F'],
4: [name:'Amy', age: 54, gender:'F']
]
def bob = people.find { it.value.name == 'Bob' } // find a single entry
def females = people.findAll { it.value.gender == 'F' }
// both return entries, but you can use collect to retrieve the ages for example
def ageOfBob = bob.value.age
def agesOfFemales = females.collect {
it.value.age
}
// ageOfBob == 32, agesOfFemales == [21,54]
def agesOfMales = people.findAll { id, person -> person.gender == 'M'}.collect { id, person ->
person.age
}
// agesOfMales == [32, 36]
// `any` returns true if any entry matches the predicate
people.any { id, person -> person.age == 54 }
Conclusion
There is a lot of information and examples here. What I hope you walk away with is an understanding of what a list and a map is, most importantly. Understanding how to use these in the API is really important, and manipulating them will save you a ton of time and unnecessary code.